PAPERS
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
https://arxiv.org/pdf/1909.11942.pdf
Introduction
- Increasing the model size when pretraining language represetnations often results in improvement on performance of downstream tasks. However, this comes at the cost of extra computing resources in terms of both memory required and speed.
- ALBERT introduces two parameter reduction techniques to improve performance of BERT without siginificant negative performance on downstream tasks
- Factorizes embedding parametrization
- Cross-Layer parameter sharingg
- ALBERT also introduces a self-supervised loss for sentence-order prediction which replaces the next sentence prediction task in BERT.
Related Work
- Previous methods have improved efficiency in either memory or speed but adversely affect the other aspect.
- Cross-layer parameter sharing has been used before but the prior work has been focused on training for standard encoder-decoder tasks rather than the pre-training/finetuning setting.
- Previous work has removed the next-sentence prediction(NSP) task for BERT when experiments showed that had no effect on performance.
Model Architecture
- The architecture is similar to BERT with transformer encoder with GELU nonlinearities.
- \(E\) is vocabulary embedding size, \(L\) is number of encoder layers, \(H\) is hidden size.
1. Factorized Embedding Parameterization:
- In BERT, the WordPiece embedding size E is tied with the hidden layer size \(H\) implying \(E\equiv H\)
- The authors argue that this is sub-optimal because these embeddings are meant to learn context-indpenedent representations whereas hidden-layer embeddings are meant to learn context-dependent representations. From previous papers, from the use of context, BERT-like representations help provide the signal for learning such context-dependent representations. Unlinking the two parametrs would make more efficient usage of the total model parameters by making it \(H\gg E\)
- Since \(E\) was originally very tied \(H\), the total number of parameters of the embedding matrix \(E\times V\) would exponentially increase by increasing \(H\). The resulting matrix would be sparse would only a few values being updated during training.
- The embedding paramers size \(O(V\times H)\) grows with increasing \(H\). ALBERT factorizes the embedding parameters into two smaller matrices with size \(O(V\times E\ +\ E\times H)\). The vectors are projected to space \(E\) first before being projected to space \(H\). This is much more significant when \(H\gg E\).
2. Cross-Layer Parameter Sharing:
- In order to improve parameter efficiency, ALBERT shared all parameters across layers. Compared to Deep Equilibrium Models which reach an equilibrium point for which the input and output embeddings of a certain llayer remain the same, ALBERT has oscillating embeddings.
3. Inter-Sentence Coherence Loss
- BERT used two pre-training tasks, masked language modelling(MLM) and next sentence prediction(NSP).
- NSP was designed to improve performance on downstream tasks that involve sentence pairs. However, later experiments and research showed that the task had minimal impact on performance.
- The reason probably beingg that NSP was much simpler than MLM and as such was not a useful task in conjuction with MLM.
- The authors argue that NSP conflates topic prediction and coherence prediction. While topic prediction is easier, it also overlaps with MLM.
- ALBERT uses sentence-order prediction which classifies whether two sentences are in the correct order or not. This new classification loss is explicitly for sentence coherence.
Evaluations
- The paper has much more detailed explanations of experiments but as a summary, ALBERT improves performance of BERT on several different tasks while also being about 1.7 times faster (ALBERT-large vs BERT-large). ALBERT-xxlarge gains the most improvements in performance with only around 70% of BERT-large's parameters. However, the structure of this model makes it 3 times slower.
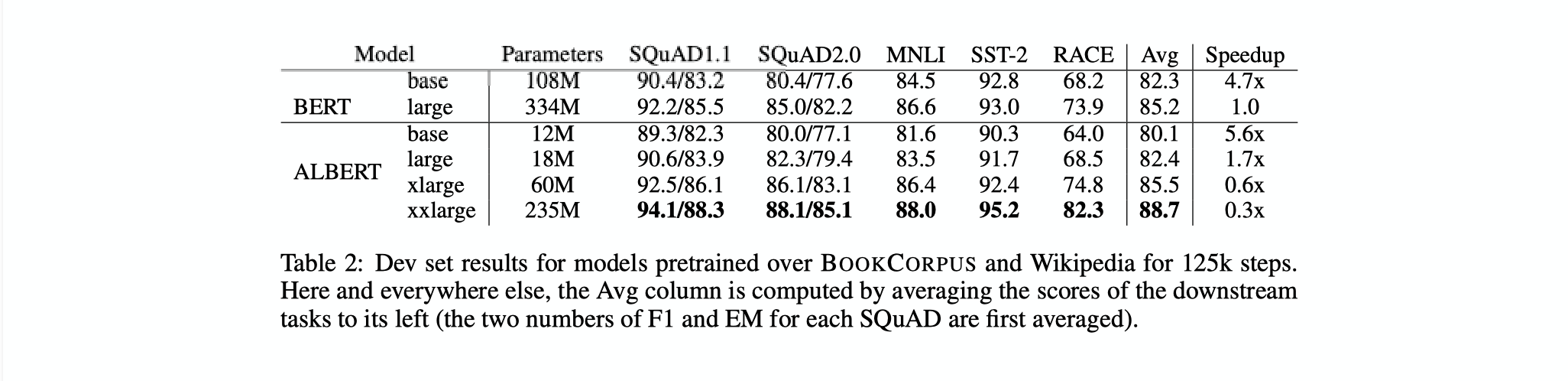
- Paper also details ablation studies and performance on GLUE tasks.
- Overall, ALBERT-xxlarge has less parameters than BERT-large but gets significantly better results while losing speed due to its large structure.