PAPERS
Deep Learning without Weight Transport
Deep Learning without Weight Transport
https://arxiv.org/pdf/1904.05391.pdf
- Current algorithms for deep learning rely on weight transport, where the weight matrices used during the forward pass are transmitted backwards during the backpropagation algorithm.
- Biologically this is likely impossible as neurons in the brain don't transfer they weights between each other. The paper proposes 2 methods which let the feedback path learn appropriate weights accurately and quickly without weigt transport.
Weight-transport problem:
\(y_{l+1}=\phi(W_{l+1}y_l+b_{l+1})\) is the forward pass equation. \(\delta_l=\phi'(y_l)W^T_{l+1}\delta_{l+1}\) is the backprop equation. Both of these use \(W\) matrix which is not proven to be possible in the brain where forward and feedback paths are physically distinct.
Method 1 - Weight Mirrors:
- Initialize random matrix \(B\) so it becomes proportional to the transpose of another matrix \(W\) without weight transport.
- \(y = Wx\). We observe that \(E[xy^T]=E[xx^TW^T]\). In the simplest case, the elements of x are independed and zero-mean with equal variance \(\sigma^2\).
- This implies \(E[xy^T]=\sigma^2W^T\)
- B can be pushed in the direction of W using
\(\Delta B=\eta_Bxy^T\)
- Over time, B may grow large so a mechanism must be implemented to prevent this.
- The network operates in 2 modes. Engaged and mirror mode.
- Engaged functions similarly to a forward pass to update \(W\).
- In mirror mode, the feedback weights \(B\) are updated using the above rule. The feedback signal \(\delta_l\) in each layer, faithfully mimics \(y_l\)
- Then the update rule becomes,
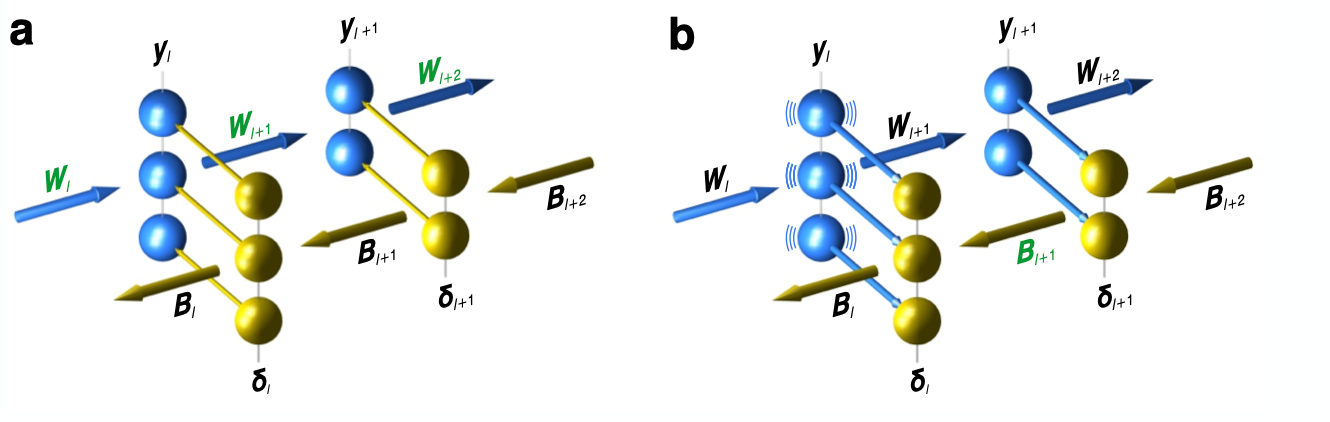
\(\Delta B_{l+1}=\eta_B\delta_l\delta_{l+1}^T\)
Proof for Weight mirrors:
\(\delta_l\delta_{l+1}^T=y_ly_{l+1}^T=y_l\phi(W_{l+1}y_l+b_{l+1})^T\)
Assume that \(\phi\) is diffrentiable everywwhere, and variance of \(y_l\) is very small such that \(W_{l+1}y_l+b_{l+1}\) falls in a rougly affine range of \(\phi\) then,
\(\phi(W_{l+1}y_l+b_{l+1})\approx\phi'(b_{l+1})(W_{l+1}y_l)+\phi(b_{l+1})\)
\(\therefore \delta_l\delta_{l+1}^T\approx y_l[y_l^TW_{l+1}^T\phi'(b_{l+1})^T+\phi(b_{l+1})^T]\)
Replacing in the expectation:
\(E[\Delta B_{l+1}]\approx\eta_b(E[y_ly_l^T]W_{l+1}^T\phi'(b_{l+1})^T+E[y_l]\phi(b_{l+1})^T)\)
\(=\eta_bE[y_ly_l^T]W_{l+1}^T\phi'(b_{l+1})^T\)
\(=\eta_bW_{l+1}^T\phi'(b_{l+1}^T)\)
So we can see that the matrix \(B\) integrates a teaching signal which is related to \(W\).
Method 2 - Kolen-Pollack Algorithm:
- Kolen and Pollack observed that we don't have to transport the weights itself if we can transport the changes in the weights. If \(W\) and \(B\) were initially unequal but undergo identical adjustments and identical weight factors
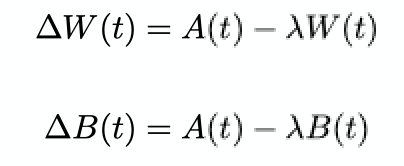
- Then,
\(W(t+1) - B(t+1) = W(t) + \Delta W(t) - B(t) - \Delta B(t) = (1-\lambda)[W(t)-B(t)] = (1-\lambda)^{t+1}[W(0)-B(0)] \)
which eventually converges to 0. - However, biologically this is still infeasible as it involves transfer between synapses.
- Instead, this method has been reworked to fit into the current paradigm. The standard, forward-path learning rule says that the matrix \(W_{l+1}\) adjusts itself based on a product of its inpit vector \(y_l\) and a teaching vector \(\delta_{l+1}\). Instead a reciprocal arrangement is proposed where synapses in the feedback adjust themselves based on their own inputs and cell-specific, scalar teaching signals from the forward path.
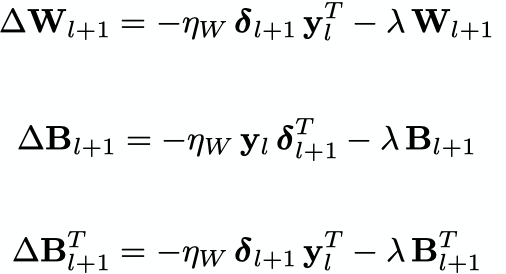
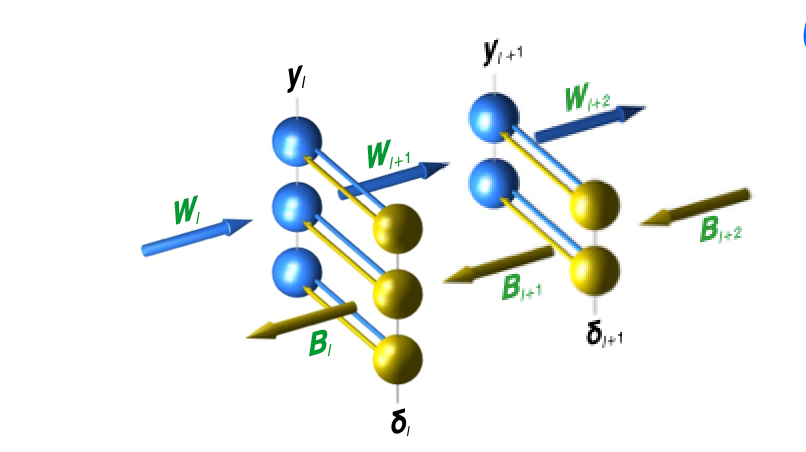
In this network, the only variables transmiited between cells and each synapse computes its own adjustment locally. However, these equations are in the form of the Kolen-Pollack equations and therefore the forward and feedback weight matrices converge to transposes of each other.
Experimental Results
- Weight mirroring and Kollen-Polack methods both manage a final top-1 test error nearly equivalent to backprop on ImageNet task.
- The forward and feedback matrices agreement were measured by taking matrix angles. This is done by reshaping each into vectors and calcuating the angles. With backprop the angle was always 0 degrees and with weight mirroring the angle remains between 6 and 12 degrees. Kollen-Pollack was even more accurate, with the angles being near 0.