PAPERS
Experience Replay for Continual Learning
Experience Replay for Continual Learning
https://arxiv.org/pdf/1811.11682.pdf
Problem
- In settings where gathering new experience is expensive/difficult it is imperative to retain gained knowledge while learning only from one task at a time.
- Boundaries between different tasks will not be persistent and this leads to the danger of catastrophic forgetting where an agent forgets what it has learned previously when it encounteres a new situtation
Solution
- An ideal continual learning system must satisfy three requirements.
- Retain learned capacities. Should not be any degradation in task performance when a previously seen task is encountered.
- Maintenance of old skills should not negatively impact the acquisition of new skills or knowledge
- If possible, continual learning should use previously learned tasks to learn new tasks faster through constructive interference or positive transfer.
- The paper proposes Continual Learning with Experience and Replay (CLEAR). Uses a mixture of novel experience on-policy and replay experience off-policy for both maintenance of performance on earlier tasks and rapid adaptation to new tasks.
CLEAR
- CLEAR uses actor-critic training on a mixture of new and replayed experiences.
- For replay experiences, does behavioral cloning between the network and its past self to prevent network output on replayed tasks from drifting while learning new tasks.
- The cloning is done on both policy and value and is implemented as a loss.
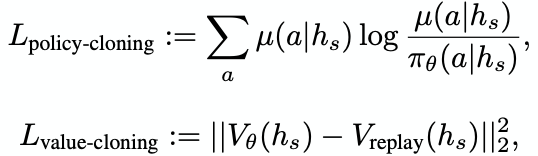
Discussion of Results
- The paper details three different methods of training on 3 separate but related image processing tasks
- Separate training where multiples networks is trained on each task separately.
- Simulataneous training where a single network trains on all tasks simultaneously
- Cyclic training where the network cycles through each task sequentially.
- While separate and simulataneous training were similar in output, cyclic training results in catastrophic interference with vanilla training.
- The use of CLEAR alleviates this problem and the task performance is closer to separate and simulataneous training.
- Balance of on- and off-policy learning:
- Ratio of new examples to replay examples effect on training is observed. With 100 percent new, this results in catastrophic forgetting. 75-25 ratio gives a goood resistance to forgetting while 100 percent training results in no forgetting but with some dip in performance
- 50-50 was found to be the ideal ratio.
- Limited-size buffers
- Buffer size of replay experience was varied between 50 million and 5 with very little pereformance drop.
- CLEAR also succeeds in learning a new task very quickly. The new task is inserted in the the cyclic sequence as a probe.
Extensions
- Algorithm that both remembers and selectively forgets certain tasks that are no longer needed or have changed drastically.
- This happens when the action space of a task is changed during training and hence the agent needs to overwrite previously learned skills.