PAPERS
Model based Reinforcement Learning for Atari
Model based Reinforcement Learning for Atari
https://arxiv.org/pdf/1903.00374.pdf
Introduction
- Model-free reinforcement learning has been used to learn effective policies for complex gaems such as Atari games just from the image observations.
- However, this requires a huge amount of iterations which is not similar to a human. This is possibly due to the fact that humans generate a model of the environment itself so that they can predict what is coming next and learn further from that.
- This paper implements a similar concept for reinforcement learning agents where they learn a model of the environment where, given an action and the current state, can predict the next state. This should reduce the amount of interactions needed to learn a game by improving sample efficieny as the model can essentially learn to peek into the future and see which actions generate desirable outcomes. The model being described in the paper is Simulated Policy Learning (SimPLe).
- SimPLe is similar to a video-prediction algorithm
- Empirical evidence shows that SimPLe is more sample-efficient than highly optimized model-free algorithms.
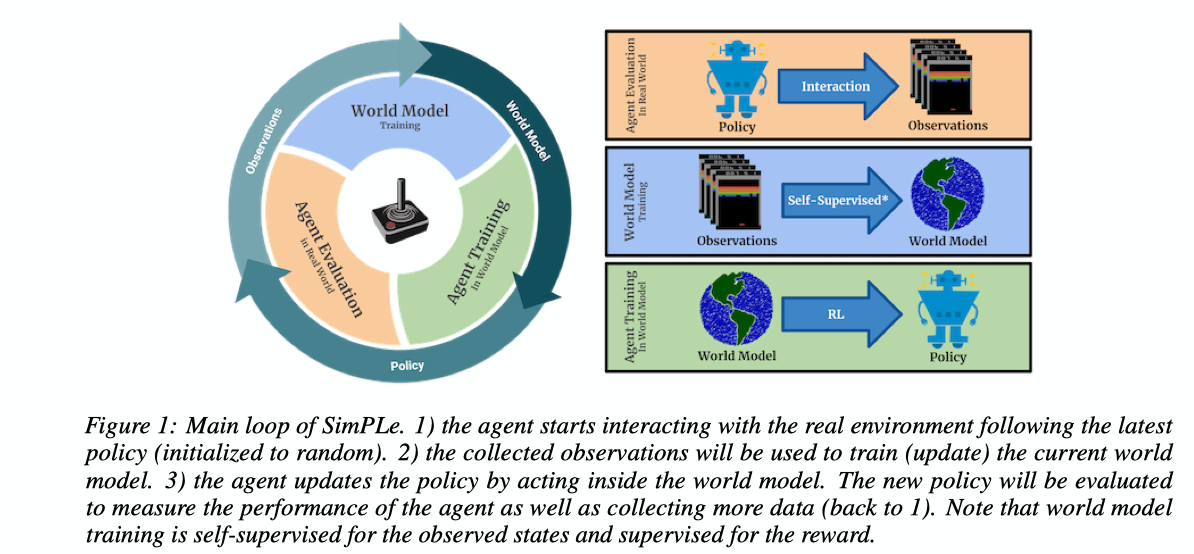
Simulated Policy Learning (SimPLe)
- Reinforcement Learning is formalized in Markov decision process (MDP) which defines a tuple (\(S,A,P,r,\gamma\)), where \(S\) is a state space, \(A\) is a set of available actions, \(P\) is unknow transtion kernel, \(r\) is reward function and \(\gamma\) is discount factor.
- The goal of a reinforcement learning algorithm is to learn a policy \(\pi\) which is a mapping from states to probability distributions over \(A\). The paper aims to find a policy in Atari 2600 games which maximizes the objective function for the policy. The crucial aspect is that apart from the \(env\) from the Atari 2600 emulator, the paper also uses a neural neetwork simulated \(env'\).
- The \(env'\) shares the action space and reward space as the normal \(env\) and is being trained to mimic the latter.
World Models
- Determininstic Model: The basic architecture consists of a convolutional feedforward network. The input \(X\) consists of four consectutive game frames and action \(a\). The actions are one-hot envoded and embedded in a vector which is multiplied channel-wise with the output of the convolutional layers. The output is the next frame of the game and the reward. Essentially training to mimic the emulator.
- Loss functions: Uses the clipped loss max which was found to be crucial for improving the models.
- Scheduled sampling: Since the model \(env'\) takes as input only the frames from \(env\), it is highly likely that an error will become compounded over time steps as the model never sees it again and has no way to correct it. The problem is mitigated by randomly replacing some frames in the input \(X\) with the predicted frames from the previous time step while linearly increasing the mixing probability to 100% around the middle of the first iteration of the training loop.
- Stochastic Models: A stochastic model was used to deal with limited horizon of past observed frames as well as sprites occlusion and flickering which results to higher quality predictions. The authors use a variational autoencoder aas an additional network which receives the input frames as well as the future targgget frame as input and approxinates the distirbbution of the posterior. At each step, a latent value \(z_t\) is sampled from this distribution and passed as input to the original predictive model.
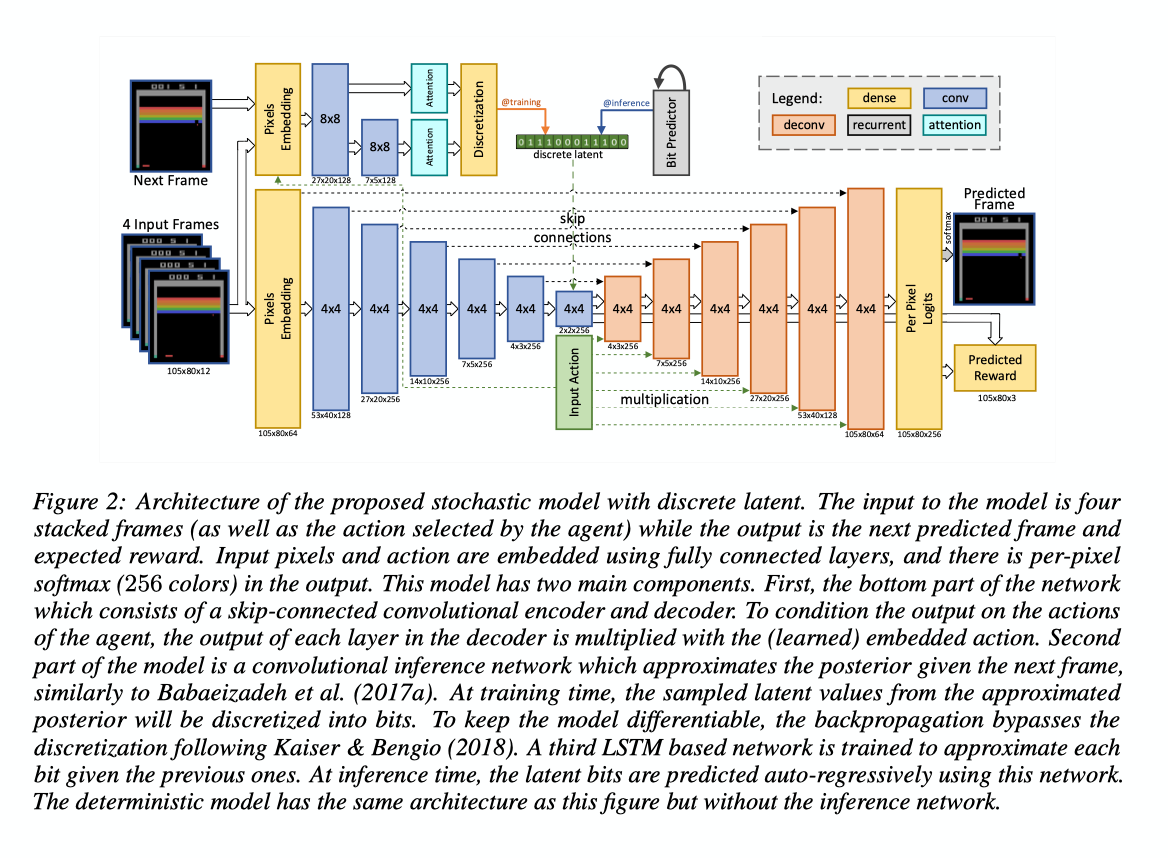
Policy Training:
- Uses proximal policy optimization algorithm (PPO). Algorithm genereates rollouts in the simulated \(env'\) and uses them to improve the policy \(\pi\).
- To mitigate the compounding of imperfections of the environment model, use shorter rollouts/
- PPO will suffer from shorter rollouts, so in the last step of a rollout, the evaluation of the value function is added as reward.

Experiments:
a. Sample Efficiency
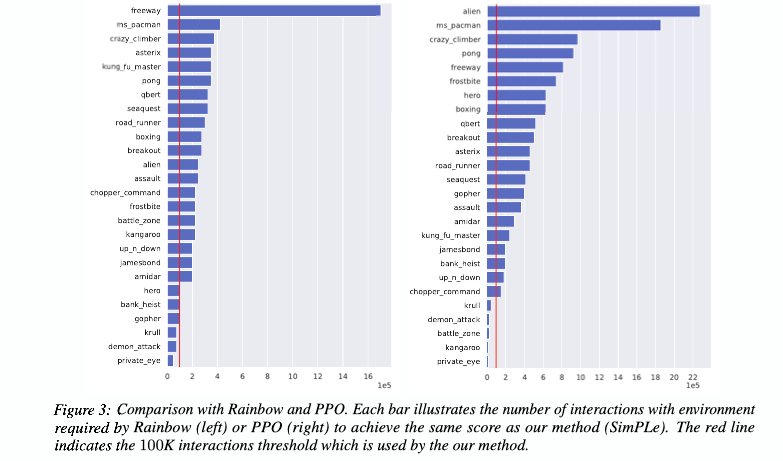
- The primary evaluation of the experiments is to compare the sample efficiency of SimPLe in comparison with SOTA deep RL methods in the literature. The authors compare with Rainbow and PPO.
- The red line illustrates the 100k threshold of SimPLe and every bar larger than this, requires more iterations to achieve a similar performance.
- SimPLe has a much better sample efficiency in a majority of the games.
b. Number of Frames
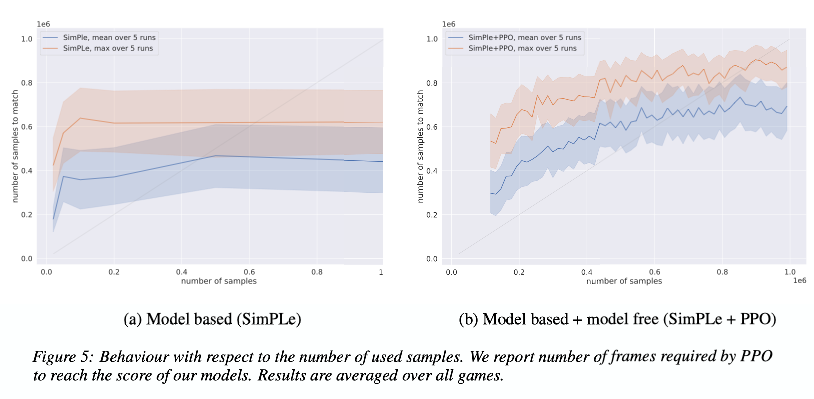
- Next, the authors varied the number of interaction steps with environment and compared it with model-free PPO.
- From the graphs, it can be seen that SimPLe excels when there is a low amount of data but model-free obtains comparable results when there is more data.
c. Environment Stochasticity:
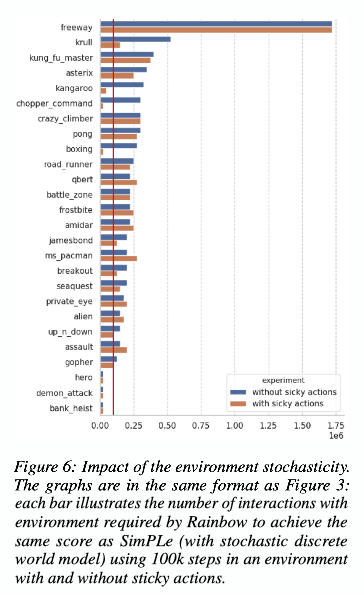
- Certain environments in Atari have an inherent randomness which can't be predicted by a deterministic world model. For example, in Kung Fu Masters a random set of enemies appear after clearing the current screen.
- Since the world model in this case is stochastic, when run on such environments, the world model learned to account for the stochasticity and performs well compared to the Rainbow algorithm on the same games.
Limitations:
- Final scores on the whole are lower than the bests SOTA model-free methods. Can possibly be improve with a better dynamics model.
- High variability between runs possibly due to number of complex interactions with the model, policy and data collection.