PAPERS
Revisiting Self-Supervised Visual Representation Learning
Revisiting Self-Supervised Visual Representation Learning
https://arxiv.org/pdf/1901.09005.pdf
Problem:
Paper deals with aspects of self-supervised learning that have been not researched thouroughly or recent enough.
Self Supervision:
- Framework for creating supervised signal automatically in order to learn representations that will be useful for downstream tasks
- Requires only unlabled data in order to formulate a pretext learning task such as predicting context
- Pretext tasks must be designed in such a way that high level understanding is useful for solving them
Architecture of CNN models:
- Paper evaluates self-supervised technique in the image domain and hence focusses on the use of CNNs.
- Uses variants of ResNet and a batch normalized VGG architecture.
Self-supervised techniques
- Rotation: Produce 4 copies of single image by rotating it by {0 \(^\text{o}\) , 90\(^\text{o}\), 180\(^\text{o}\), 270\(^\text{o}\)} and tasks the model with classifying the rotation.
- Exemplar: Individual images correspond to their own class and other members of the class are generated by heavy random data augmentation such as translation, scaling, rotation and contrast and color shifts. Uses a triplet loss whcih encourages examples of the same image to have representations that are close in the Euclidean space
- Jigsaw: Model has to recover relative spatial position of 9 randomly sampled iamge patches after a random permutation of these was performed
- Relative patch location: Model is similar to the Jigsaw one. Receives two patch of an image and needs to predict one of the 8 possible spatial relations between the two patches
Evaluation of Learned Visual Representations:
- The learned representations are evaluated by using them in downstream tasks. The tasks used in this paper are multiclass image classifcation tasks.
- Datasets used are ImageNet and Places205
Experimental Results
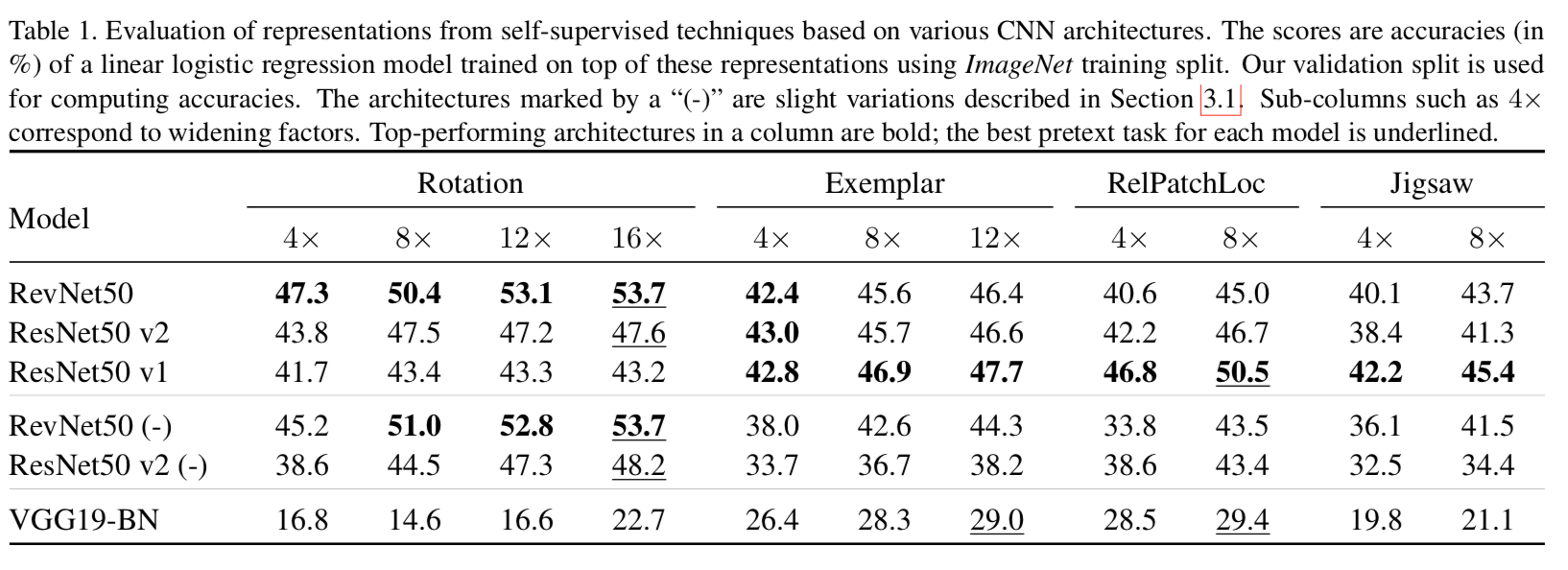
- Similar models often learn self-supervised visual representations that make them significantly different in performance
- The rankings of architectures across the self-supervised tasks is not consistent. The ranking of methods across the architectures is also not consistent
- One clear observation is that increasing number of channels in CNN models imrorves performance of the self-supervised models. This is similar to supervised model methods
Observations:
- Better performance on pretext task does not always translate to better representations
- Good performance is useful as an evaluation of potential of the model but only after the model has been fixed.
- This can't be used to reliably select the model architecture
- Skip connection prevent degradation of representation quality towards the ends of CNNs.
- Authors believe this happens because the model overfit to the pretext task in the later layers and disscard more general semantic features present in the middle layers
- This holds true only for VGG and not for ResNet. Authors believe that this is a result of ResnNet's residual units being invertible under some conditions
- Model width and representation size positively influence the representation quality when the sizes are increased.