PAPERS
ViLBERT
ViLBERT
Problem
- Currently the dominant strategy for vision-and-language tasks is to pretrain models for the two domains separately and then attempt learn visual grounding by training them together
- However, this approach does not accurately capture the relations between visual and linguistic features and how they effect one another.
- Need a model that is pre-trained for visual grounding.
Solution:
- Paper presents a joint model for learning task-agnostic visual grounding from paired visiolinguistic data which is called Vision & Language BERT.
- Uses separate streams for vision and language processing, but these streams communicate using co-attentional transformer layers. Provides interaction between the different streams at various depths.

Extending BERT to jointly represent Images and Text:
- ViLBERT consists of two parallel BERT-style models operating over image regions and text segments.
- Each stream is a series of transformer blocks (TRM) and co-attentional transformer layers (Co-TRM) which is introduced to enable information exchange between the two modalities.
- Given a text input ($w_0,...,w_T$) and region features ($v_1,...,vT$) the model outputs final representions $(h{v0},..,h_{vT})$ and $(h_{w0},..,h_{wT})$. The interaction between the streams is limited to only certain layers.
-

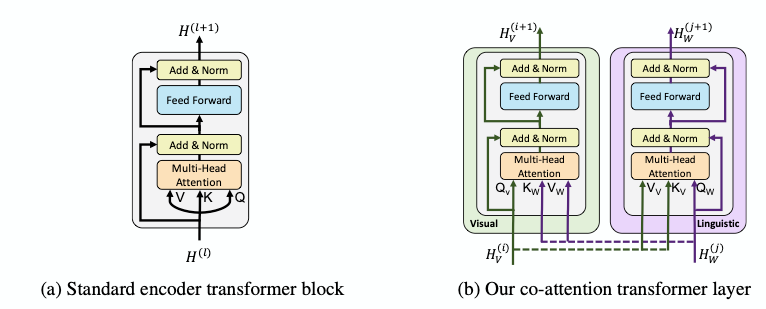
Co-Attentional Transformer Layers:
- Given intermediate visual and linguistic representations ${H_V}^{(i)}$ and ${H_W}^{(j)}$, the model computes the query, key and value matrices as in a standard transformer block.
- However, the keys and values from each modality is passed as input to the other modality's multi-headed attention block. This causes the attention block to produce features for each modality conditioned on the other
Training:
- Two pre-training tasks are considered: masked multi-modal modelling and multi-modal alignment prediction.
- The masked multi-modal task is similar to what is used in standard BERT. Masked image regions have image features zeroed out 90% of the time.
- In multi--modal alignment task, the model is present an image-text pair and must predict whether the image and text are aligned correctly.
Vision-and-Language Transfer Tasks:
- A fine tuning strategy of modifying the pre-trained model to perform the new task and then train the entire model end-to-end is used.
- Visual Question Answering
- Visual Commonsense Reasoning
- Grounding referring Epressions
- Caption-Based Image Retrieval
- Zero-shot Caption-Based Image Retrieval
Results
- ViLBERT does better than single stream models on downstream tasks.
- Pre-training ViLBERT using proxy tasks improves performance
- Finetuning from ViLBERT, transfer task performance exceeds state-of-the-art task specific models for the 4 tasks